


.jpg)


If you’re reading this, it’s safe to say that you’re already doing a pretty solid job of tracking your product data. You’re probably generating piles of data on your users’ activities every day—how users are interacting with your product, what features they’re using, how frequently they’re being used, and so on. But just how much mileage are you really getting out of this data?
When it comes to tracking product data, chances are that you are using some type of general analytics tool (which is nothing more than a dumb query interface), which allows you to pull up and visualize your product data in various ways. Perhaps you’re taking this one step further, making this data available to other teams in order to help them make decisions and drive specific actions. You might even be using Segment.com to facilitate this distribution (which I couldn’t recommend more).
However, very few people are taking things to the next level by infusing their raw data with context , giving it meaning, and making their product data not only accessible, but actually useful to other teams within their organization.
Why your existing product data needs more context
Raw data is good. However, for many people, it’s just not that helpful, and it’s definitely not scalable. Sure, for those brilliant data analysts, raw data is awesome. In fact, data analysts prefer the data to be as raw as possible!

However, when you are trying to leverage data in order to drive decisions and actions, it needs to be easier to consume. This is especially true when you are trying to scale the decisions and actions that can be derived from this data across a wide group of people.
Let’s take credit data as an easy example. The average adult’s credit history includes mounds of raw data, all of it super valuable. But without any context, how useful is it?
Raw credit data looks a little something like this:
- January 2010: Opened credit card
- May 2010: Car loan issued — principal $13,500
- June 2011: Late payment on car loan
- July 2012: Applied for mortgage
- August 2012: Late payment on car loan
- Feb 2013: Opened credit card
- Feb 2014: Credit card limit extended
- May 2014: Car loan balance paid in full
- May 2014: Mortgage issued — principal $159,400
- July 2014: Credit card balance paid in full
- Dec 2015: 90-day delinquency on mortgage payment
Based on this raw credit data alone, would you be able to tell if this individual’s credit history is good or bad? If you were a bank, would you lend to this person? How would you make that decision?
If a creditor had to weed through all of this raw data every time they were assessing a loan, well, there wouldn’t be many loans issued. Not only would take an enormous amount of time to weed through this type of data, but it would also be near impossible to leverage for decision-making purposes.
By just looking at this data on its own, some might think, “Three late payments over 5 years? That’s terrible! Reject him the bum!”
But what if told you that the average potential borrower had six late payments over a typical five year period? Hm….maybe this individual’s credit history isn’t looking so bad.
However, what if I then told you that 8% of the population had zero late payments over five years? Oh…interesting. So this guy’s not terrible, but not perfect, either.
Now, what if I told you that this borrower was in the bottom 25% of credit holders in terms of length of credit history? Well…jeez.
The point is, this raw data is really meaningless without the right context. No lender could ever be expected to make a good, fast decision based upon raw data alone.
Enter credit scores.
Credit scoring models take in all of this raw data and spit out a contextual number that is actually useful. They weigh certain factors (like payment history) more than other factors (like total amount owned), crunch the numbers, and churn out a single number. And with a scoring model, it all becomes pretty simple to determine that someone with a 750 credit score is a better borrower than someone with a 670 credit score.
The best part is, it’s scalable. Any type of creditor — mortgage lenders, car companies, rental agencies, etc. — can use this same number to drive their decisions.
In short, it’s helpful, actionable, and scalable. Because it has context.
Adding context to your product data
One of the best ways to add valuable context to your existing product metrics is by creating a way to score your product engagement. Like with credit scoring, product engagement scoring gives your product data the essential context necessary for every part of your organization that relies on it.
Ultimately, this contextual product data is essential for:
- Helping Sales assess trial leads. If you have a free trial or freemium model, tracking activation metrics will help sales prioritize their efforts.
- Allowing Marketing to build more relevant and effective messaging. For most SaaS business, much of your messaging should be shaped and triggered based on engagement (or lack thereof).
- Prioritizing customer success efforts. Targeting upsells, saving failing accounts, providing highly relevant support—all of this can (and should) be driven by account-based engagement metrics.
- Helping the board make future investment decisions. Strong user engagement is indicative of future success. Poor engagement is, well, not.
With context, this type of data can—and should—become a foundation for much of how you conduct your business.
How Sherlock handles engagement scoring
While Segment.com has provided a tremendous service for making product metrics available, Sherlock was designed to make this data useful.

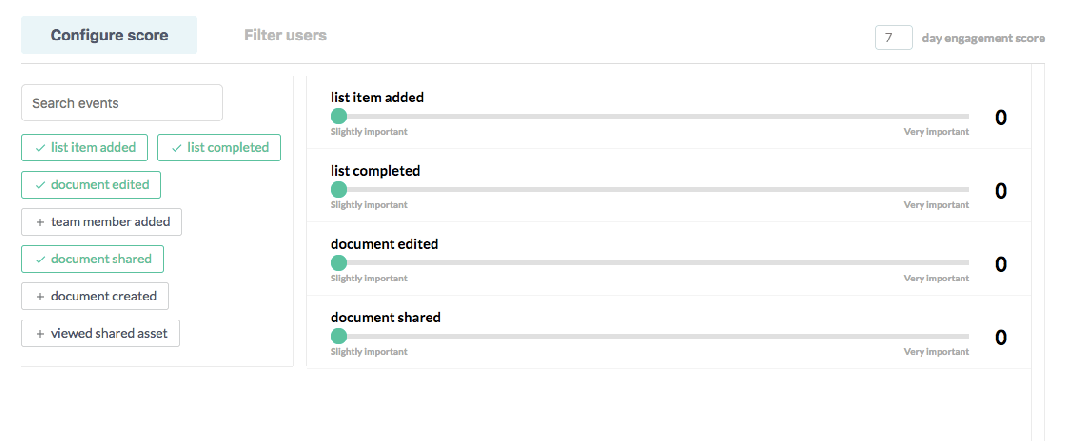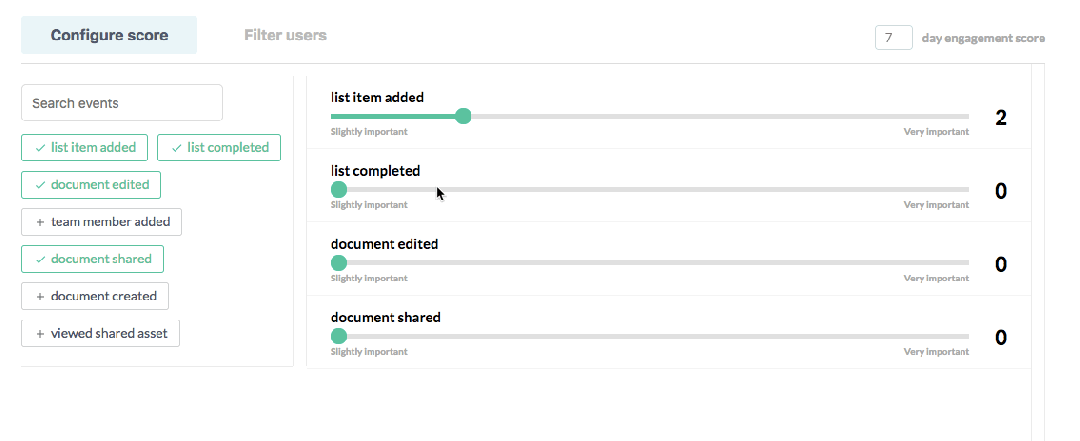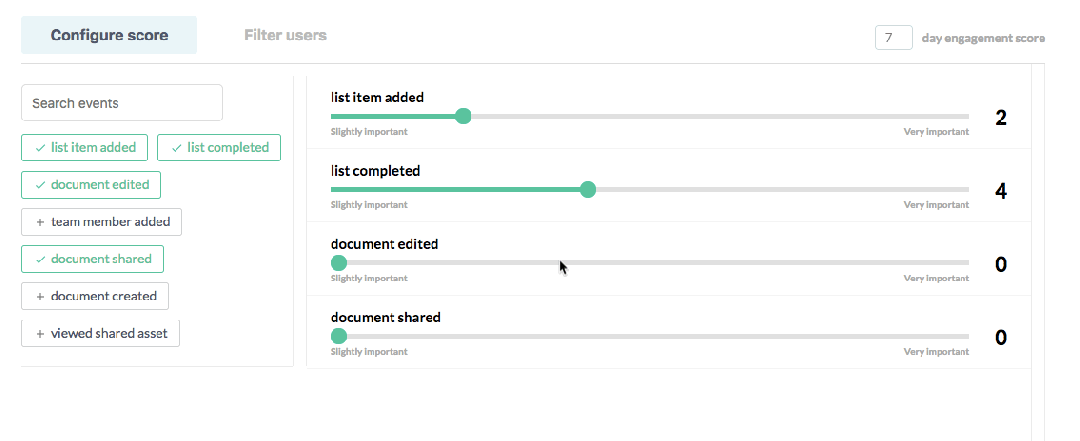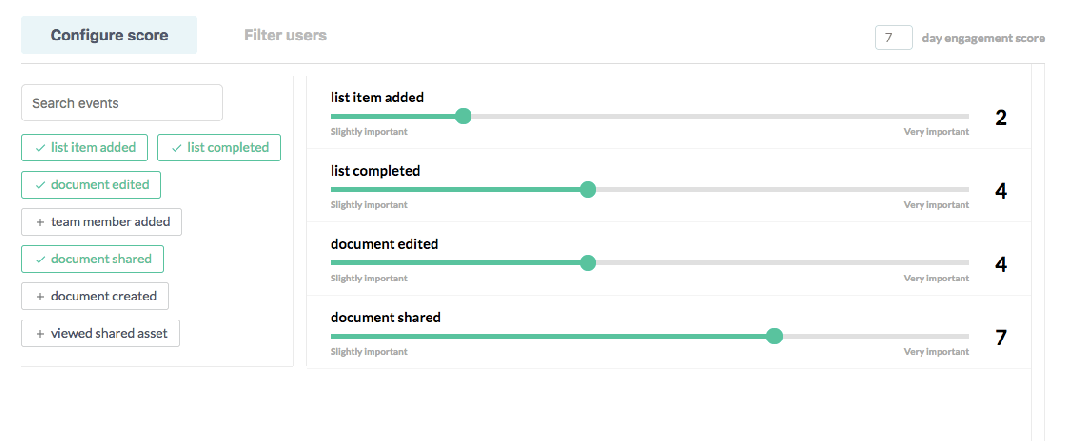
In Sherlock, users create their own scoring model by weighing their important product events based on each event’s importance to overall engagement, much like a credit score. With this simple configuration, Sherlock builds a model that gives every user of the product a normalized score between 1–100.
As you can imagine, these normalized scores make your product engagement data helpful. They allow you to understand engagement like never before. Sherlock leverages these user-level scores to score and rank:
- All of your active users
- Each of your accounts
- All product features (based on engagement)
- Segments of users
- The engagement of your product over time

All of this data can be easily consumed because it’s all contextual. More importantly, this scoring model enables product data to be much more useful and actionable across your entire organization.
Start taking your product data to the next level
Don’t settle for weeding through a bunch of raw data to derive meaning. And certainly, don’t make the rest of your organization wrestle with your raw data in order to make their functional decisions.
Whether or not you use Sherlock to help with this, you should definitely be looking to give your product data more context. To help you get started on your own, we’ve created a step-by-step blog post on how to track product engagement.
The fact is, SaaS organizations that make decisions and take actions based on actual user data simply operate at a higher level. As a product leader, you should be striving to make this as easy as possible for the team. Facilitate the transformation of your product metrics and get the entire organization to the next level.
If you’d like to see how Sherlock can help add valuable context to your existing product metrics, you can start a free trial or request a demo.
A version of this post was originally shared on ProductCoalition.com.
More Posts



Track and communicate your Product data schema with this Notion template
Over the last several months, we have moved our knowledge base to Notion. One of the last pieces we brought over was our product data schema (we used to track it in Github, then we moved it to a Dropbox Paper doc).

5 Things Your SaaS Sales Team Needs to Know About Product Engagement
The SaaS business model has long challenged the need for the traditional software salesperson. The SaaS model – and more recently the push toward Product-Led Growth with its free trial and frictionless upgrade path – has called for the death of sales.